
Vision
4.5 Architectures |
Architectures are of great importance in the design and realisation of information systems. In information technology there are two meanings to the term architecture: the architecture of a specific computer system and architecture as the style of building.
The architecture of a specific system
The architecture is a model indicating how a system is roughly divided into components and how these components collaborate to realise the functions of the system. Usually, there is a collection of models that together represent the complete architecture of a system. In case of the application of IT in business operation, separate models are needed for the architectures of the business processes and business objects, the applications and the hardware configuration. The models may be static, like a data model and hardware configurations. Nowadays, simulation tools also allow for dynamic models, such as the simulation of how a business process works, or how hardware components work.
Architecture as the style of building
An architecture as the style of building is a set of rules indicating how we can construct systems from components. There are standards for the way components should work and especially for the way they should connect.
This section goes into architectures as the style of building, and especially application architectures. As a result of the advent of network systems there is a strong interest in application architectures. The hardware of a network system consist of workstations (e.g. personal computers) that are connected to server computers (e.g. mid-range computers or a mainframe) via a network.
A network architecture of the hardware allows for the development of applications that consist of different components which run on different computers in the network and exchange messages.
To be able to build this type of applications, it must be agreed on beforehand which components applications may consist of, on which computers they may run and how they communicate. You therefore need an application architecture, a style of building, prescribing how developers should construct these distributed applications.

Figure 4.5 Network architecture of the hardware. We here discuss two application architectures for network systems. The first one is the, currently booming, client/server architecture. As a starting point, this architecture uses applications in the form of existing on-line programmes, indicating how these applications can be distributed among workstations and servers/ The second architecture we discuss is based on object orientation. Typical of this architecture are autonomous active objects (agents) on different computers, that collaborate. We have called this architecture the Collaborative Object Architecture.
4.5.1 Client/Server Architecture
In the client/server architecture, an application at least consists of a component on the workstation - the client - that uses the services of components - the servers - on mid-range computers or the mainframe.
In the client/server architecture, clients and servers are separate programmes. To execute an application, the user starts the client on his workstation. The client calls the server on the server computer and starts it.
The Gartner Group distinguishes five types for the division of tasks among clients and servers. These are based on the fact that an application consists of three functions, being the presentation to the user, the application logic of the actual processing and the data management for retrieval and editing of data in the database.
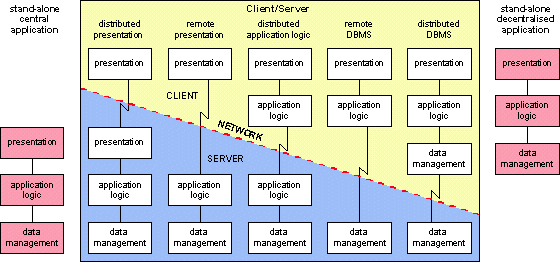
Figure 4.6 Five different types of client/server architecture (source: Gartner Group).
The five types of client/server are briefly described below.
Distributed Presentation
In this type, almost all the intelligence is located in the server. The workstation only handles part of the presentation. An example of this is an application running on the mainframe with the presentation handled by a Character User Interface on the workstation. This is not a particularly interesting form of client/server, since it is, for example, impossible for a server on a mainframe to control a Graphical User Interface on a personal computer.
Remote Presentation
In this type, the client handles the presentation on the workstation, preferably via a GUI, while the server handles the application logic and the data management. A condition is that the application logic is able to properly control the presentation on the GUI. This is not possible if the server is a conventional transaction programme on the mainframe.
Distributed application logic
This type splits the application logic into two parts. Besides the presentation, the client mainly handles the process logic of the application, such as displaying and handling windows via the GUI. Besides the data management, the server also handles the data logic of the application, such as reading and editing data and verification and security. This type of client/server can be used very well with a client on the personal computer with a GUI for the presentation and one or more servers on a mainframe or on mid-range computers, in the form of a conventional on-line programme (without presentation, though). The server can also be realised as a so-called remote procedure of a relational DBMS.
Remote DBMS
In this type, all the intelligence of the application is placed in the client. The server is in fact a DBMS. This type is currently much used in PC-LAN environments with a PC or mid-range computer for a server. A relational DBMS has been installed on the server. The clients on the workstations communicate with a relational DBMS through SQL-queries.
Distributed DBMS
This type of client/server is hardly ever applied, since DBMSs do not yet properly support a distributed database.
Which type of client/server architecture is the best one, strongly depends on the situation.
4.5.2 Collaborative Object Architecture
A disadvantage of the types of client/server architecture described above, is the fact that they can only be used for one type of application, namely on-line transactions with which the user retrieves and edits data in databases. They exclude two important types of applications:
- 'groupware' applications, which for example support the communication and collaboration between different users;
- distributed applications with (massive) parallel processing, which can also serve to replace existing batch applications.
Both cases concern applications which can be very well supported by network systems.
Another point is the fact that in the client/server architecture an application is still a programme, in which the data are stored separately in a DBMS. This implies that we have to distribute programmes as well as data over the network separately. Especially in a distributed environment there are therefore advantages to having objects as applications. We can then distribute objects over the network as units of data, functions and interfaces.
We have to aim for an architecture in which the various application components collaborate in a different form. In the current client/server architecture this collaboration has the form of Co-operative Processing. This is the name for the collaboration in an application between a client, for example on a workstation, and one or more servers on for example a mainframe or mid-range computer. The user starts the client, which in turn calls the servers, so there is a 1 to n co-operation between client and servers. This is a form of hierarchic co-operation. The client and the user usually wait for the server to answer. The server is not capable of executing an assignment independently during a long period of time, or of calling in the help of another user, if it receives an order it cannot execute.
What we are aiming for is an architecture with Collaborative Processing. This is the name for a n to m relationship between independent application components. This type of co-operation can be realised between autonomous, self-operating objects which are located on one computer or on different computers in a network and communicate with each other. Such autonomous objects are called agents. Typical of an application consisting of agents is the fact that the agents can be active parallel on different locations in the network. Agents that function as servers can decide for themselves when they execute the user's orders. Agents can communicate with each other, they make requests of each other and return answers. Agents are also able to contact the user via the interface and ask him specific questions or display messages.
Figure 4.7 shows the architecture that supports collaborative processing between objects. We have called this architecture Collaborative Object Architecture.
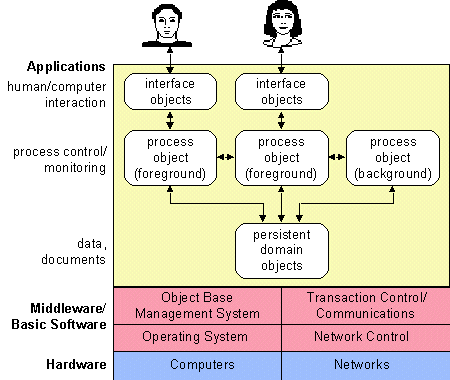
Figure 4.7 Collaborative Object Architecture. In this architecture, the applications consist of three different types of objects: interface objects, process objects and domain objects.
Interface objects
The interface objects handle the man/computer interaction via a GUI or a multimedia interface. There are also interface objects that support the communication with printers and scanners.
Process objects
The process objects support the processes the users execute. An example of a process object is an electronic work file that supports the execution of an administrative process by various users. Process objects can communicate with each other, which makes them able to support communication between processes and between users. A process object can be active in the foreground, communicating with the user via interface objects, or in the background, communicating with other process objects.
Many process objects correspond with business processes, of which they handle the automated part of the execution.
Domain objects
The domain objects contain data related to a certain application domain, for example customers, products and contracts. Users want to keep these data for a long period to use them in the processes they execute. Domain objects therefore are of a persistent nature.
Many domain objects correspond with business objects, of which they handle the execution of the automated functions, including the recording of data.
The Collaborative Object Architecture is in fact a client/server/server architecture consisting of clients in the form of interface objects, process servers in the form of process objects and data servers in the form of domain objects. It is a variation on the 'distributed application logic', in three layers:
- the presentation logic for a GUI or a MUI;
- the process logic;
- data and the logic for retrieval and editing.
Agents
The essential difference between the architectures is found in the additional layer of process logic, consisting of process objects. These process objects are agents that handle their own real-time operation. The difference between agents and ordinary 'passive' objects lies in the way they handle requests from the user, via interface objects, or requests from other objects.
Passive objects immediately handle a request and then returns a result. Making requests of passive objects works like a subroutinecall, the requester has to wait for the object to answer.
An agent is able to 'tell time', and can therefore decide for itself when it handles a request. Passive objects and agents regard the requests made of them as events they have to handle. Passive objects do so immediately, but agents decide for themselves when they do so. As a results, applications not only become event-driven, but also are of a real-time nature. Agents handle two types of events: external events and internal events.
External events
An external event is a request the agent receives from a user, through an interface object, or from another agent. An agent may receive several requests at once and can decide for itself when it handles a request or when it returns the answer. The user or agent making the request, does not wait for an answer. When the agent has handled the request, it displays an answer to the user through an interface object, or it returns an answer to the requesting agent.
Various possibilities are open to the agent as to when it handles a request. Like a passive object, it can handle requests immediately, or it can collect requests of the same type and handle them in batches. It can also handle a request at a later point in time. This gives the user the possibility to make requests of the agent which it handles for instance the next day, or weekly. Agents can deal with requests which take a long time to handle, since the user does not have to wait for an answer.
An agent can also control processes involving several users. The first user starts the agent, which then handles the process according to 'schedule', involving other users via interface objects.
Internal events
Agents may also be activated by so-called internal events. If an agent has a request to handle at a certain point in time, it places a reminder in an internal diary. As the moment arrives, the agent becomes active and handles the request. The same mechanism can be used for a request to handle something periodically, for example a request to calculate the interest on a savings account on a yearly basis.
When an agent makes a request of another agent without waiting for an answer, it places a reminder in the diary as to when it expects an answer. If the answer is returned in time (an external event), the reminder is cancelled. If the answer is late, the passing of the moment becomes an internal event, and an error procedure is started. This mechanism can also be applied to make sure customers are answered in time.
Supporting functions for agents
Figure 4.8 shows the working of an automated system according to the Collaborative Object Architecture. The implementation uses three functions that support the agents in working as described above. These supporting functions are available on every computer in the network. This allows for the distribution of the objects among workstations and server computers.
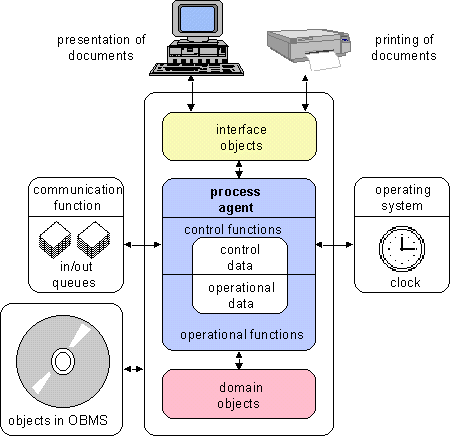
Figure 4.8 Automated system with agents. The supporting functions referred to are the Object Base Management System (OBMS), the communication function and the transaction monitoring function.
Object Base Management System (OBMS)
All applications are also supported by an OBMS in which all of the data and functions of the objects are stored. The OBMS serves as a parking lot for all agents and objects that are temporarily inactive, for example agents waiting for other objects to answer their requests. The operating system restarts the agent as soon as the answer is received, or when at a certain time an answer has not yet been received.
The communication function
The communication function supports the communication between agents. The agents may either be located on one computer or on different computers in the network. The communication function supports queues of requests and answers between agents. This is necessary because agents may receive requests from different sides, and may also have requests pending with other objects, the answers to which may also return simultaneously. An agent needs queues to be able to decide for itself when to handle requests or returning answers. The communication function can also offer all kinds of functions for telecommunications, such as locating people and places in the network.
Transaction monitoring
There must be a general transaction monitoring function (preferably as part of the operating system) which handles the starting of agents at the occurrence of internal or external events. The transaction monitor starts an agent in the OBMS when the communication function places a request or an incoming answer in a queue for the agent. This starting may happen on a priority basis or when the queue contains a certain number of requests. The transaction monitor also starts an agent when a user, through the interface object, asks a question for the first time. Moreover, the transaction monitor handles the starting of an agent in the OBMS when an action that is in the diary has to be executed. The transaction monitor provides the 'clock', as it were, in which the agent can see it is time to perform certain actions. It also has an alarm clock function which activates the agent when it has to do something at a certain time.
Composition of an agent
Like an ordinary object, an agent consists of data and functions, but besides operational behaviour, the agent also has controlling behaviour.
For this, besides operational data and the corresponding operational functions it also contains control data and control functions. An agent is in fact a cluster of objects, a flexible construction of control objects and operational objects.
Objects an agent uses may be for instance:
- a 'diary', in which the agent keeps track of the requests it still has to handle;
- a 'journal' in which the agent keeps track of the requests it has handled;
- a 'schedule' for a process to be executed (for agents managing complete processes);
- an 'acquaintance circle' of users, other agents, interface objects and domain objects that agent knows and is allowed to communicate with;
- geographical knowledge about locations in the computer network;
- the 'composition' of the agent from control objects and operational objects.
Possible applications for agents
The possibilities of agents are best illustrated by a number of possible applications.
Electronic work dossier
An agent in the form of an electronic work dossier supports the work flow and the execution of an administrative process carried out by various employees. Chapter 3 contains a full description of an electronic work dossier.
Electronic
In an agent in the form of an electronic diary, the user can keep a record of his appointments. The diary keeps track of the user's whereabouts, knows at which workstation he is working and knows whether the user can be reached by telephone or fax.
Complex searches
Users can use process server agents to perform complex searches in the network. They may concern searches for data, people or locations. From its own location, an agent then sends requests to agents on other locations, for example to trace certain data traced and have it retrieved from the various locations.
Process control and monitoring
Agents can also perform functions such as process control and monitoring. In an industrial environment, an agent is linked to the manufacturing process to be controlled through interfaces. The agent keeps a record of the progress of the process and controls it on the basis of time, prescribed procedures and conditions that occur during the process.
Electronic markets
A network of agents can also form an electronic market, in which the agents act as suppliers on behalf of a supplying party, or as requesters on behalf of a requesting party.
Parallel processing
Agents support parallel processing. An agent can make parallel requests of other agents or of domain objects. If these objects run on different processors, parallel processing of the requests is possible. The agent waits until it has received all the answers from the various objects, and then continues its process. This parallel distributed processing may also serve to replace existing large batch systems on one central computer, such as bank entry systems. A number of these systems will be facing the problem that the are incapable of handling the growing amount of daily transactions in 24 hours.
4.5.3 Middleware
In order to realise applications according to the client/server architecture and the Collaborative Object Architecture, special software is needed to bridge the gap between operating systems of computers and networks and the clients and servers of the applications. This software is called middleware. Middleware is supposed to support the design, development, management and execution of distributed applications over various hardware platforms.
The main ingredients of middleware for the client/server architecture are:
- a relational DBMS;
- a TP monitor for transaction monitoring (if this is not handled by the DBMS or the operating system);
- software for network communication between clients and servers;
- tools for network management;
- GUI software;
- development tools for clients and servers;
- tools for distributed configuration management and version management of software and databases;
- tools for remote installation and management of software and databases.
Currently, there is an ample choice of middleware from a large number of suppliers. The choice is a difficult one for users, and there is no standardisation whatsoever. Moreover, with respect to a number of essential aspects, middleware is still being developed. This concerns:
- the support of distributed server logic by DBMSs (possibly in combination with a distributed TP monitor);
- configuration and version management;
- software distribution;
- security of both the network and the distributed database;
- portability of the software, to allow for the simple installation of clients and servers on different types of hardware;
- combining custom applications with software packages.
4.5.4 Summary
The development of application systems according to client/server and object-oriented architectures is still in full swing. The middleware to support the development, management and use of these systems does not yet offer all of the functionality required. On top of this, there are too many suppliers who all have their own standards. This obstructs the combination of applications of different backgrounds (custom and package) into one system. There are also limits to the portability of applications over hardware from different suppliers.
As soon as these barriers have been lifted and developers have gained more experience, a strong growth of distributed applications can be expected. The reason for this is the fact that there are advantages to the distribution of applications over the computer network, such as increased functionality for the end user, more flexible applications and a better use of the available hardware capacity.
The further growth of networks into an information superhighway will eventually lead to the connection of the computer systems of companies and people's home systems, thus creating world-wide distributed applications. The first world-wide application, already available on the Internet, is World Wide Web. At their personal computers, by means of a client programme running under Microsoft Windows, users can open documents other participants have made available on the network. The documents consist of texts and pictures and can refer to each other by means of hyperlinks.